Understanding inode in Linux systems

An inode is a file(everything in a Linux is a file!!!) which stores information on how and where data of a file is stored in blocks in the hard disk. If inode usage reaches 100%, no new files can be created in a server.
Here is Wikipedia definition
The inode (index node) is a data structure in a Unix-style file system that describes a file-system object such as a file or a directory. Each inode stores the attributes and disk block locations of the object's data.
File System uses an algorithm to provide the next inode value and to be unique, inode number of pre-created when a file system is initialized in an ext4 file system.
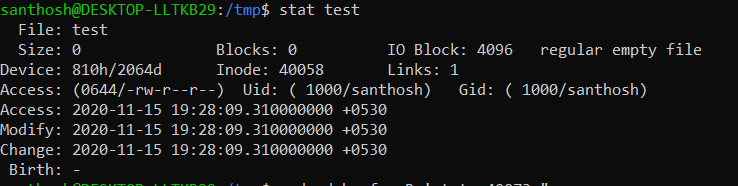
An inode stores the following information pertaining to a file or directory
- File type: regular file, directory, pipe etc.
- Permissions to that file: read, write, execute
- Link count: The number of hard links relative to an inode
- User ID: the owner of a file
- Group ID: group owner
- Size of file: or major/minor number in case of some special files
- Timestamp: access time, modification time and (inode) change time
- Attributes: immutable' for example
- Access control list: permissions for special users/groups
- Link to the location of a file
- Other metadata about the file
Inode metadata
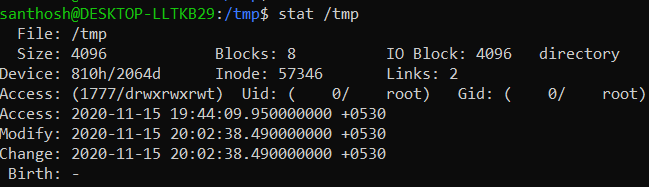
Using stat command, one can see the inode details
Output of a regular file
Output for a directory
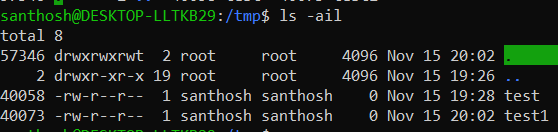
To list all the files along with inode numbers ls -ih or ls -ilh can be used

Ever wondered how cd .. changes PWD to parent dir?
Whenever a new directory is created, by default 2 files are created in it (. & ..). One can see that the inode of . is of the folder(57346) and that of .. is the inode of the parent directory(2 in this case as it's /). This is the reason why cd .. takes us to the parent directory.
File Operations
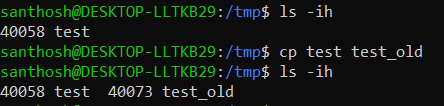
Copy operation
During a copy, as data is duplicated, the new/copied file gets a new inode number.
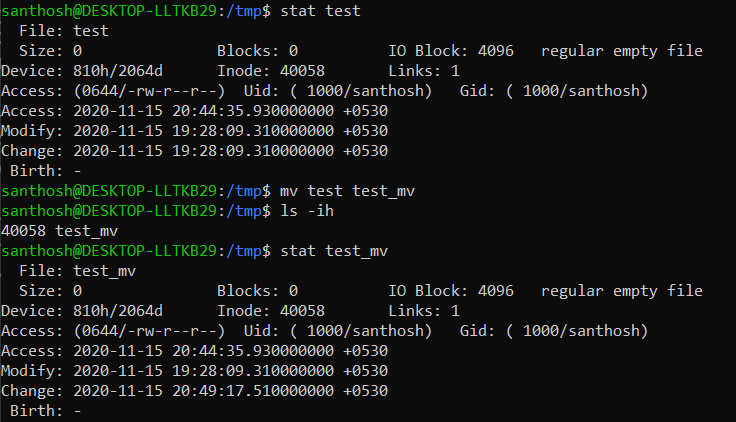
Move operation
During move operation, the file name just gets updated in the inode metadata without any operations on the data block. That's the reason why a move is faster than a copy for huge files.
Hard & Soft links
A soft link is similar to file copy i.e., two files with different inodes are created. The difference is that inode of the soft link file contains data to redirect to the original file

As both soft link and original file are separated, on deleting the source, redirection doesn't get affected and error is printed

Hardlink has two file names with the same inode number
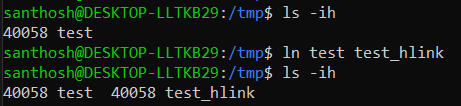
As two files refer to the same data block, the number of links is shown as 2

Deleting a link file decrement the number of links as expected.

This inode way of storing information has its own limitations. Even for small data, inode first needs to be obtained and from the information obtained, data needs to be sought again in Dataspace.




